Data analysis is hard.
What makes it hard is the intuitive aspect of it - knowing the direction you want to take based on the limited information you have at the moment. Additionally, it's communicating the results and showing why your analysis is right that makes this all the more difficult - doing it deeply, at scale, and in a consistent fashion.
Having been a part of many of these deep-dive analyses, I've noticed some "principles" that I've found useful to follow throughout.
Know your approach
Before you begin the analysis, know the questions you're trying to answer and what you're trying to accomplish - don't fall into an analytical rabbit hole. Additionally, you should know some basic things about your potential data - what data sources are available to answer the questions? How is that data structured? Is it in a database? CSVs? Third-party APIs? What tools will you be able to use for the analysis?
Your approach will likely change throughout, but it's helpful to start with a plan and adjust.
Know how the data was generated
Once you've settled on your approach and data sources, you need to make sure you understand how the data was generated or captured, especially if you are using your own company's data.
For instance, let's say you're a data scientist at Amazon and you're doing some analysis on orders. Let's assume there's a table somewhere in the Amazon world called "orders" that stores data about an order. Does this table store incomplete orders? What is the interaction on Amazon.com that creates a new record in this table? If I start an order and do not fully complete the payment flow, will a record have been written to this table? What exactly does each field in the table mean?
You need to know this level of detail in order to have confidence in your analysis - your audience will ask these questions.
Profile your data
Once you're confident you're looking at the right data, you need to develop some familiarity it. Not only will this allow you to gain a basic understanding of what you're looking at, but it also allows you to gain a certain level of comfort that things are still "right" later on in the analysis.
For example, I was once helping a friend analyze a fairly large time series dataset (~10GB). The results of the analysis didn't intuitively jive with me - something felt off. When digging deeper into the analysis, I decided to plot the events by date and noticed we had two days without any data - that shouldn't have been the case.
Profiling your data early on helps to ensure your work throughout the analysis - you'll notice sooner when something is "off."
Facet all the things
I'm increasingly convinced that Simpson's Paradox is one of the most important things for anyone working with data to understand. In cases of Simpson's paradox, a trend appearing in different groups of data disappears when the groups are combined and looked at in aggregate. It illustrates the importance of looking at your data by multiple dimensions.
As an example, take a look at the below table.
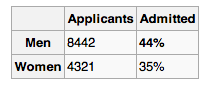
The above table shows admission rates for men and women into the University of California, Berkeley's graduate programs for the fall of 1973. Based on the above numbers, the University was sued for an alledged bias against women. However, when faceting the data by sex AND department, we see women were actually admitted into many departments' graduate programs at a rate higher than men.
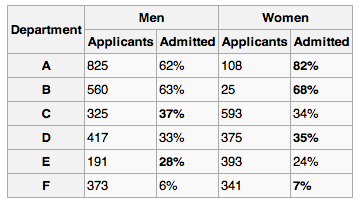
This is probably the most infamous case of Simpson's paradox. The folks over at Berkeley's VUDLab have put together a fantastic visualization allowing you to explore the data further.
When going through your data, do so with Simpson's paradox in mind. It's extremely important to understand how aggregate statistics can be misleading and why looking at your data from multiple facets is necessary.
Be skeptical
In addition to profiling and faceting your data, you need to be skeptical throughout your analysis. If something doesn't look or feel right, it probably isn't. Pore through your data to make sure nothing unexpected going on, and if there is something unexpected, make sure you understand why it's occurring and are comfortable with it before you proceed.
I'd argue that no data is better than incorrect data in most cases. Make sure the base layer of your analysis is correct.
Think like a trial lawyer
A good trial attorney will prepare their case while also considering how the opposition might respond. When the opposition does present, our attorney will (hopefully) have prepared for that very piece of new evidence or testimony, easily allowing he/she to counter in a meaningful way.
Much like a good trial attorney, you need to think ahead and consider the audience of your analysis and the questions they might ask. Preparing appropriately for those will lend to the credibility of your work. No one likes to hear "I'm not sure, I didn't look at that" and you don't want to be caught flat-footed.
Clarify your assumptions
It's unlikely that your data is perfect and it probably doesn't capture everything you need to complete a thorough and exhaustive analysis - you'll need to hold some assumptions throughout your work. These need to be explicitly stated when you're sharing results.
Additionally, your stakeholders are crucial in helping you determine your assumptions. You should be working with them and other domain experts to ensure your assumptions are logical and unbiased.
Check your work
It seems obvious, but people just don't check their work sometimes. Understandably, there are deadlines, quick turnarounds, and last minute requests; however, I can assure you that your audience would rather your results be correct than quick.
I find it useful to regularly check the basic statistics of the data (sums, counts, etc.) throughout an analysis in order to make sure nothing is lost along the way - essentially creating a trail of breadcrumbs I can follow backwards in case something doesn't seem right later on.
Communicate
Lastly, the whole process should be a conversation with stakeholders - don't work in a silo. It's possible your audience isn't necessarily concerned with decimal point accuracy - maybe they just want to understand directional impact.
In the end, remember that data analysis is most often about solving a problem and that problem has stakeholders - you should be working with them to answer the questions that are most important; not necessarily those that are most interesting. Interesting doesn't always mean "valuable."