This is part of a series of posts I have written about web scraping with Python.
- Web Scraping 101 with Python, which covers the basics of using Python for web scraping.
- Web Scraping 201: Finding the API, which covers when sites load data client-side with Javascript.
- Asynchronous Scraping with Python, showing how to use multithreading to speed things up.
- Scraping Pages Behind Login Forms, which shows how to log into sites using Python.
Update: Sorry folks, it looks like the NBA doesn't make shot log data accessible anymore. The same principles of this post still apply, but the particular example used is no longer functional. I do not intend to rewrite this post.
Previously, I explained how to scrape a page where the data is rendered server-side. However, the increasing popularity of Javascript frameworks such as AngularJS coupled with RESTful APIs means that fewer sites are generated server-side and are instead being rendered client-side.
In this post, I’ll give a brief overview of the differences between the two and show how to find the underlying API, allowing you to get the data you’re looking for.
Server-side vs client-side
Imagine we have a database of sports statistics and would like to build a web application on top of it (e.g. something like Basketball Reference).
If we build our web app using a server-side framework like Django [1], something akin to the following happens each time a user visits a page.
- User’s browser sends a request to the server hosting our application.
- Our server processes the request, checking to make sure the URL requested exists (amongst other things).
- If the requested URL does not exist, send an error back to the user’s browser and direct them to a 404 page.
- If the requested URL does exist, execute some code on the server which gets data from our database. Let’s say the user wants to see John Wall’s game-by-game stats for the 2014-15 NBA season. In this case, our Django/Python code queries the database and receives the data.
- Our Django/Python code injects the data into our application’s templates to complete the HTML for the page.
- Finally, the server sends the HTML to the user’s browser (a response to their request) and the page is displayed.
To illustrate the last step, go to John Wall’s game log and view the page source. Ctrl+f or Cmd+f and search for “2014-10-29”. This is the first row of the game-by-game stats table. We know the page was created server-side because the data is present in the page source.
However, if the web application is built with a client-side framework like Angular, the process is slightly different. In this case, the server still sends the static content (the HTML, CSS, and Javascript), but the HTML is only a template - it doesn’t hold any data. Separately, the Javascript in the server response fetches the data from an API and uses it to create the page client-side.
To illustrate, view the source of John Wall’s shot log page on NBA.com - there’s no data to scrape! See for yourself. Ctrl+f or Cmd+f for “Was @“. Despite there being many instances of it in the shot log table, none found in the page source.
If you’re thinking “Oh crap, I can’t scrape this data,” well, you’re in luck! Applications using an API are often easier to scrape - you just need to know how to find the API. Which means I should probably tell you how to do that.
Finding the API
With a client-side app, your browser is doing much of the work. And because your browser is what’s rendering the HTML, we can use it to see where the data is coming from using its built-in developer tools.
To illustrate, I’ll be using Chrome, but Firefox should be more or less the same (Internet Explorer users … you should switch to Chrome or Firefox and not look back).
To open Chrome’s Developer Tools, go to View -> Developer -> Developer Tools. In Firefox, it’s Tools -> Web Developer -> Toggle Tools. We’ll be using the Network tab, so click on that one. It should be empty.
Now, go to the page that has your data. In this case, it’s John Wall’s shot logs. If you’re already on the page, hit refresh. Your Network tab should look similar to this:
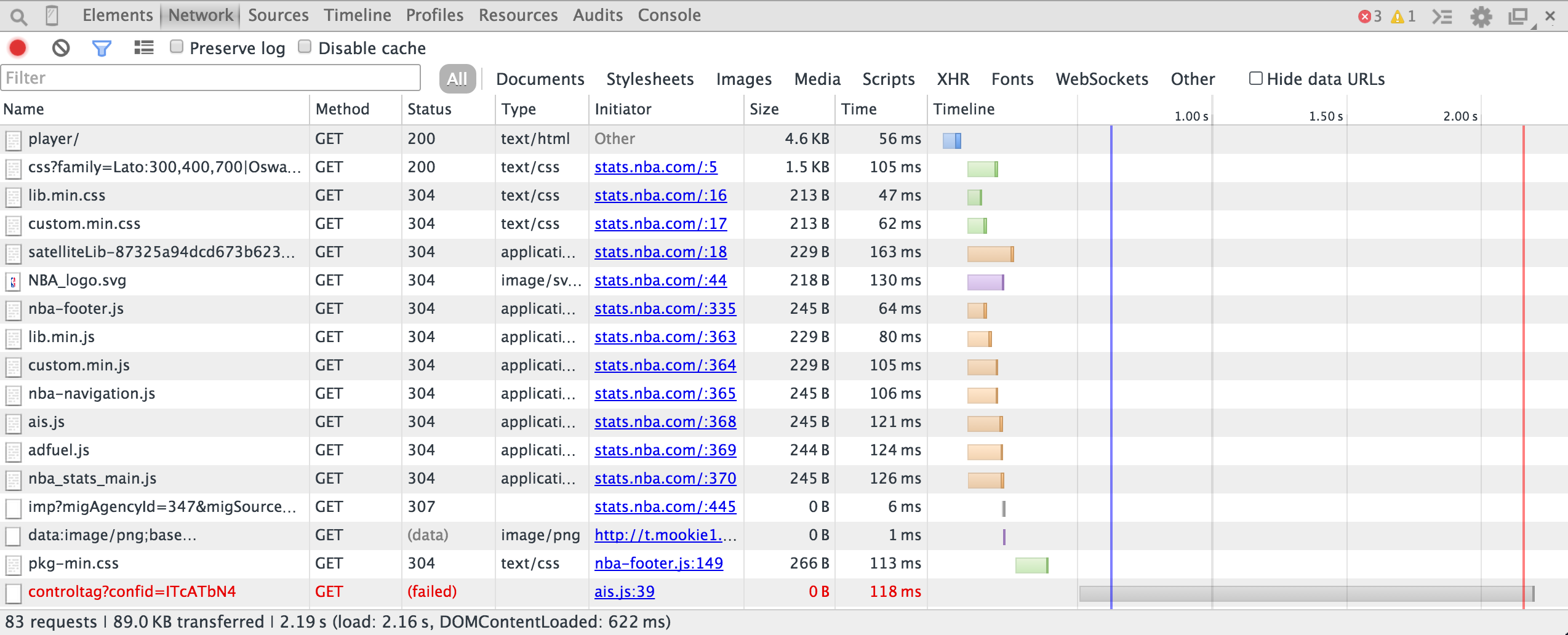
Next, click on the XHR filter. XHR is short for XMLHttpRequest - this is the type of request used to fetch XML or JSON data. You should see a couple entries in this table (screenshot below). One of them is the API request that returns the data you’re looking for (in this case, John Wall’s shots).
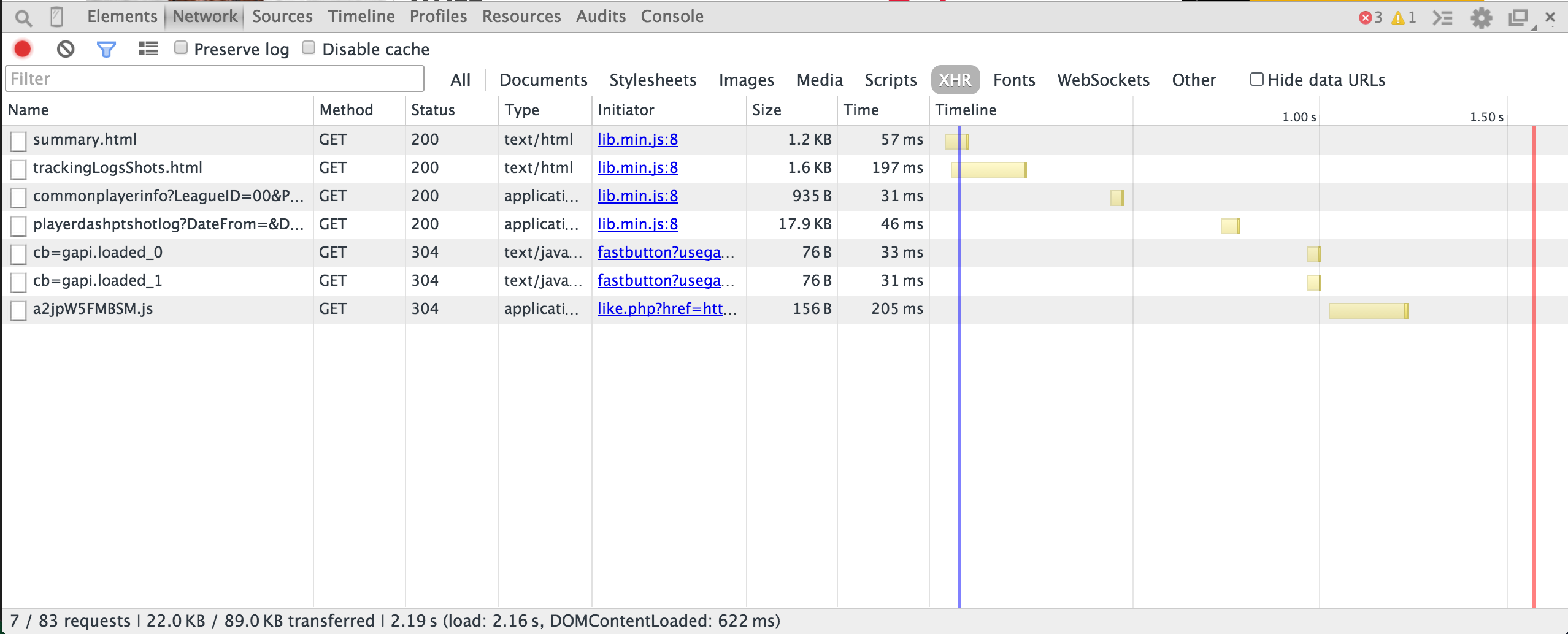
At this point, you’ll need to explore a bit to determine which request is the one you want. For our example, the one starting with “playerdashptshotlog” sounds promising. Let’s click on it and view it in the Preview tab. Things should now look like this:
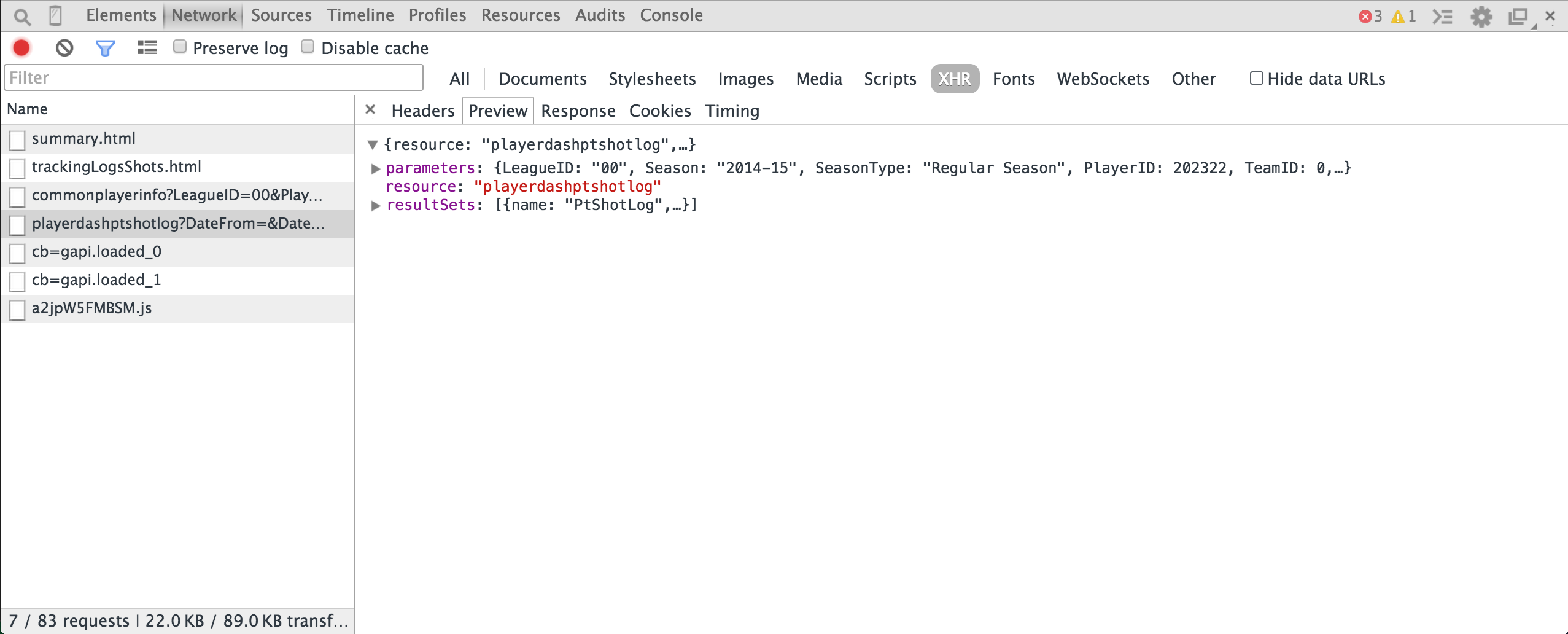
Bingo! That’s the API endpoint. We can use the Preview tab to explore the response.
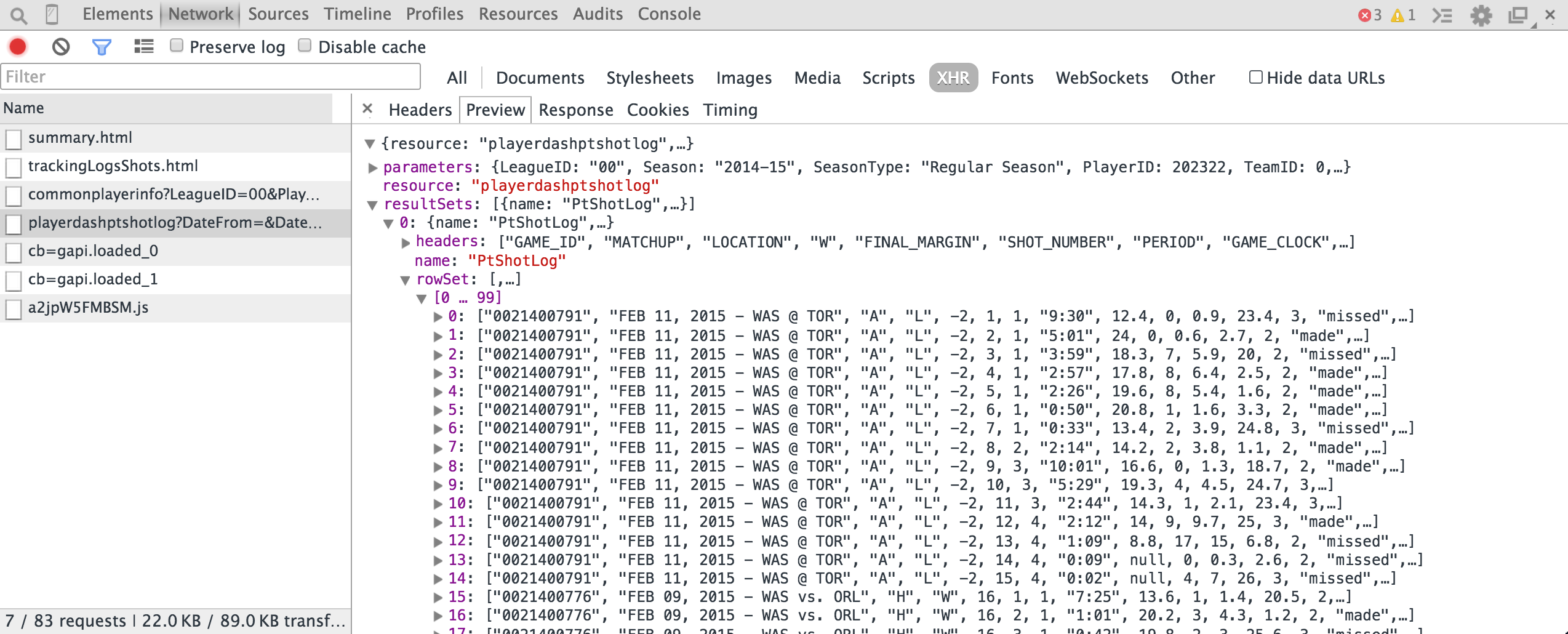
You should see a couple of objects:
- The resource name - playerdashptshotlog.
- The parameters (you might need to expand the resource section). These are the request parameters that were passed to the API. You can think of them like the
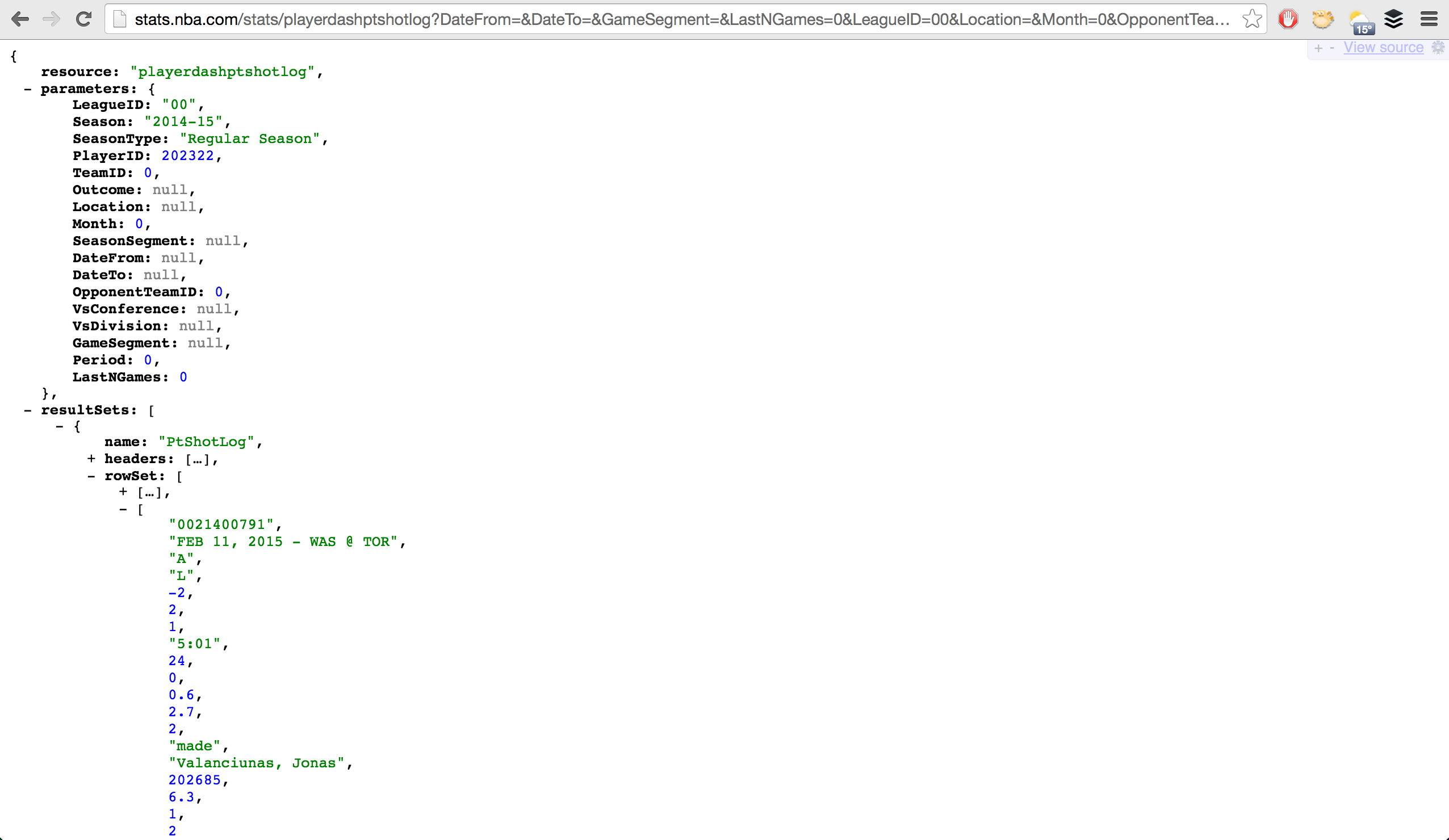
WHEREclause of a SQL query. This request has parameters ofSeason=2014-15andPlayerID=202322(amongst others). Change the parameters in the URL and you’ll get different data (more on that in a bit). - The result sets. This is self-explanatory.
- Within the result sets, you’ll find the headers and row set. Each object in the row set is essentially the result of a database query, while the headers tell you the column order. We can see that the first item in each row corresponds to the Game_ID, while the second is the Matchup.
Now, go to the Headers tab, grab the request URL, and open it in a new browser tab, we’ll see the data we’re looking for (example below). Note that I'm using JSONView, which nicely formats JSON in your browser.
To grab this data, we can use something like Python’s requests. Here’s an example:
import requests
shots_url = 'http://stats.nba.com/stats/playerdashptshotlog?'+ \
'DateFrom=&DateTo=&GameSegment=&LastNGames=0&LeagueID=00&' + \
'Location=&Month=0&OpponentTeamID=0&Outcome=&Period=0&' + \
'PlayerID=202322&Season=2014-15&SeasonSegment=&' + \
'SeasonType=Regular+Season&TeamID=0&VsConference=&VsDivision='
# request the URL and parse the JSON
response = requests.get(shots_url)
response.raise_for_status() # raise exception if invalid response
shots = response.json()['resultSets'][0]['rowSet']
# do whatever we want with the shots data
do_things(shots)
That’s it. Now you have the data and can get to work.
Note that passing different parameter values to the API yields different results. For instance, change the Season parameter to 2013-14 - now you have John Wall’s shots for the 2013-14 season. Change the PlayerID to 201935 - now you have James Harden’s shots.
Additionally, different APIs return different types of data. Some might send XML; others, JSON. Some might store the results in an array of arrays; others, an array of maps or dictionaries. Some might not return the column headers at all. Things are vary between sites.
Had a situation where you haven't been able to find the data you're looking for in the page source? Well, now you know how to find it.
Was there something I missed? Have questions? Let me know.
[1] Really this can be any server-side framework - Ruby on Rails, PHP’s Drupal or CodeIgniter, etc.